Paper Reading: A Closer Look at Skip-gram Modeling
Guthrie, D., Allison, B., Liu, W., Guthrie, L., & Wilks, Y. (2006, May). A closer look at skip-gram modelling. In Proceedings of the fifth international conference on language resources and evaluation (LREC’06).
Related Work
Method
- defining and manipulating data beyond the words in the text(part-of-speech tags, syntactic categories, etc.)
- using some form of smoothing to estimate the probability of unseen text
Drawback
Data sparsity: language is a system of rare events, so varied and complex, that even using an extremely large corpus, we can never accurately model all possible strings of words.
Skip-grams
Definition
A technique largely used in the field of speech processing, whereby n-grams are formed but in addition to allowing adjacent sequences of words, we allow tokens to be “skipped”.
Define k-skip-n-grams for a sentence w_1 … w_m to be the set
\[\{w_{i_1},w_{i_2},...,w_{i_n} | \sum_{j=1}^n i_j - i_{j-1} < k\}\]k-skip include (k-1)-skip, (k-2)-skip, 1-skip, and 0-skip
Example
| method | result |
|---|---|
| raw input | I hit the tennis ball |
| 2-grams(bi-grams) | i hit, hit the, the tennis, tennis ball |
| 1-skip-bi-grams | i hit, i the, hit the, hit tennis, the tennis, the ball, tennis ball |
| 2-skip-bi-grams | i hit, i the, i tennis, hit the, hit tennis, hit ball, the tennis, the ball, tennis ball |
| 3-grams(tri-grams) | i hit the, hit the tennis, the tennis ball |
| 1-skip-tri-grams | i hit the, i hit tennis, i the tennis, hit the tennis, hit the ball, hit tennis ball, the tennis ball |
Experiments
Data
Training data
- British National Corpus: 100 million word balanced corpus of British English
- English Gigaword: over 1.7 billion words of English newswire from 4 distinct international sources
Testing data
- 200,000 words of new feeds: from the Gigaword Corpus
- Eight Recent News Documents: from the Daily Telegraph
- Google Translations: seven different Chinese newspaper articles of approximately 500 words each were chosen and run through the Google automatic translation engine to produce English texts.
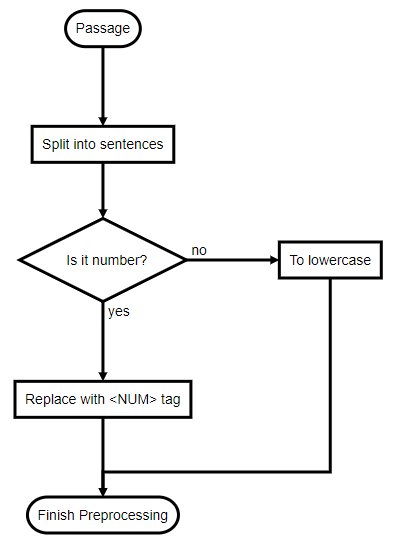
Pre-processing
Evaluation Technique
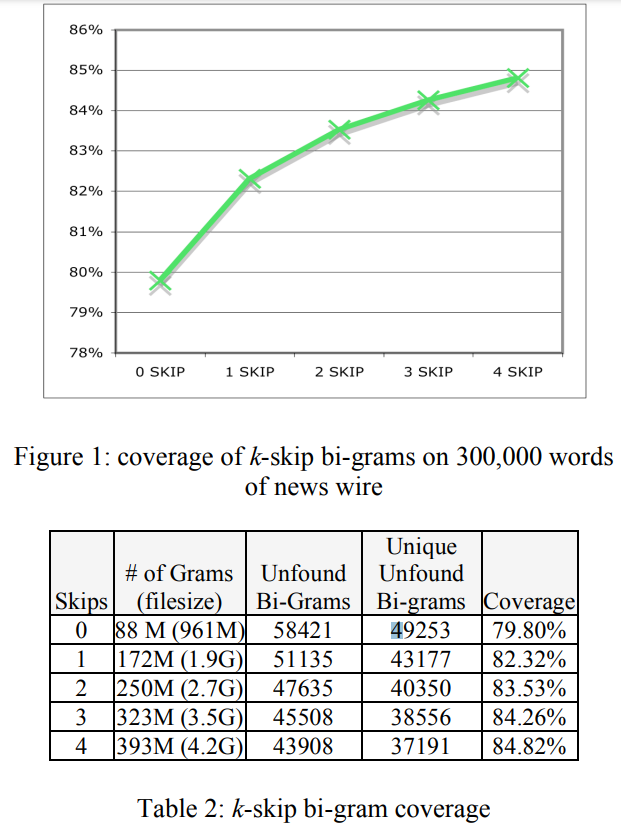
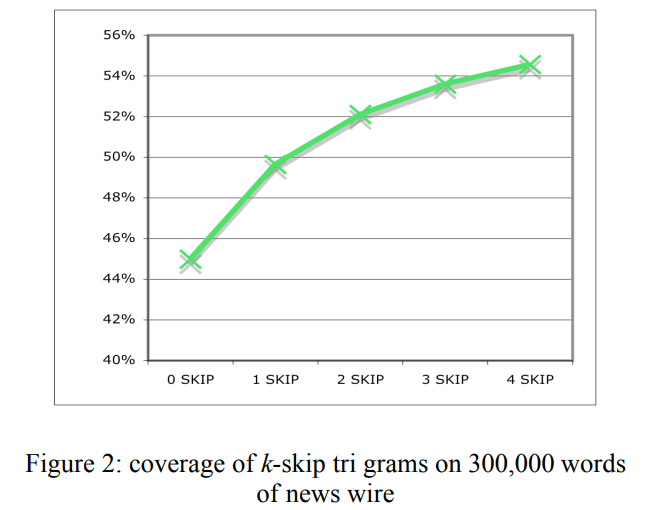
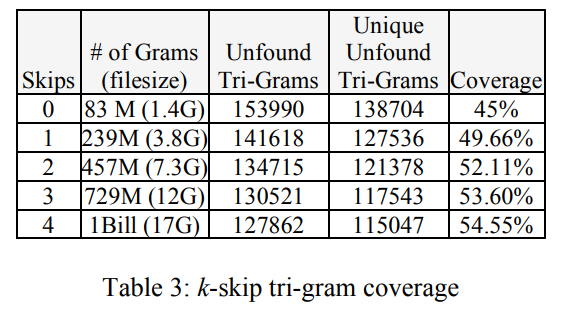
Coverage: compute all possible skip-grams in the training corpus and measure how many adjacent n-grams these cover in test documents.
Result
Coverage
| K-skip bi-gram | k-skip tri-gram |
|---|---|
 |
  |
Skip-gram usefulness
Documents about different topics, or from different domains, will have less adjacent n-grams in common than documents from similar topics or domains.
Skip-grams are accurately modeling context, while not skewing the effects of tri-gram modeling.
Skip-grams or more training data
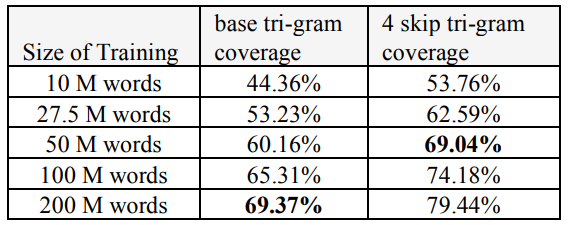
Skip-grams can be surprisingly helpful when test documents are similar to training documents.