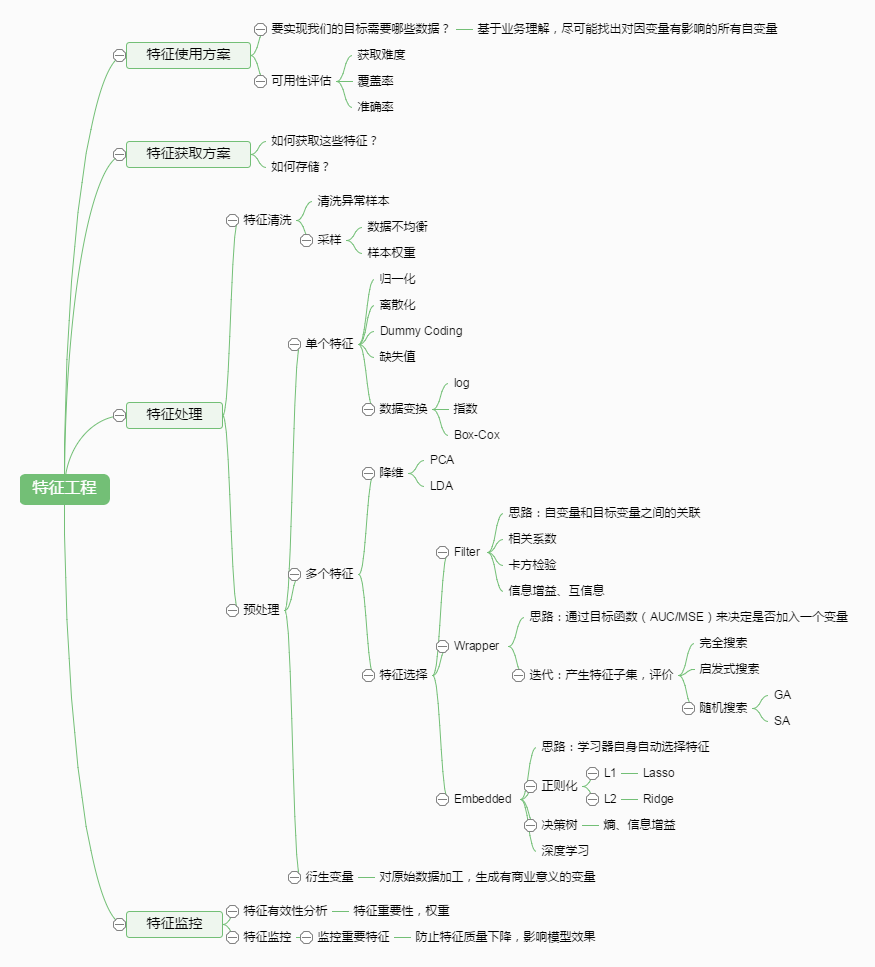
利用领域知识和现有数据,创造出新的特征,用于机器学习算法。
“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”
参考链接:
特征工程是什么
数据预处理
特征理解
结构化数据 & 非结构化数据
以表格形式存储的数据称为结构化数据,不呈现明显结构的数据称为非结构化数据,类似文本、报文、日志等。
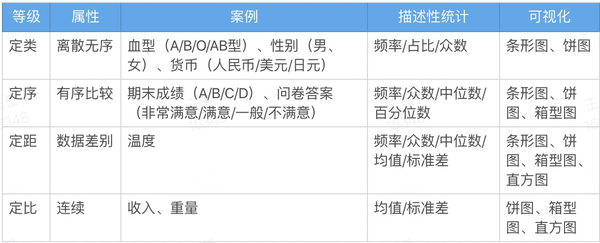
定量 & 定性数据
- 定量数据
- 定性数据
 )
)
特征清洗
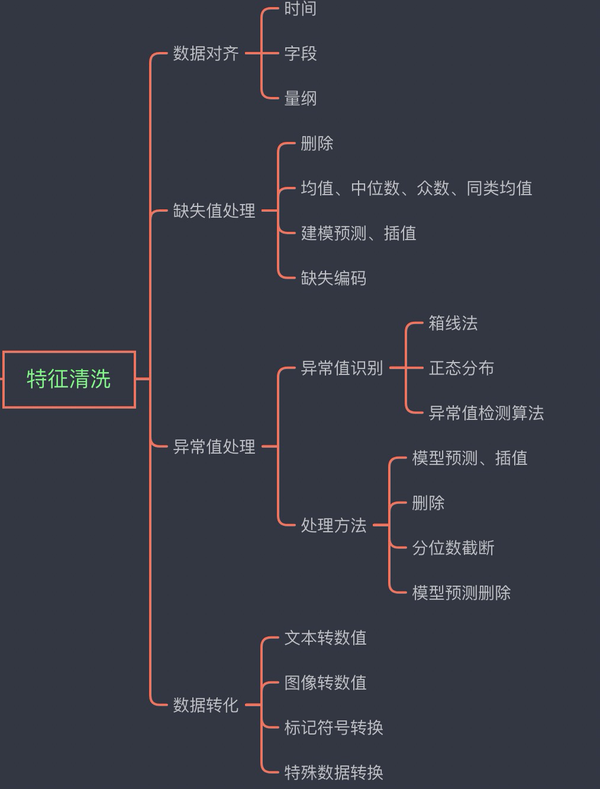
数据对齐
时间
- 格式不一致
- 时间戳单位不一致
- 使用无效时间表示
字段
- 填写错误
量纲
- 量纲不统一
- 数值类型不统一
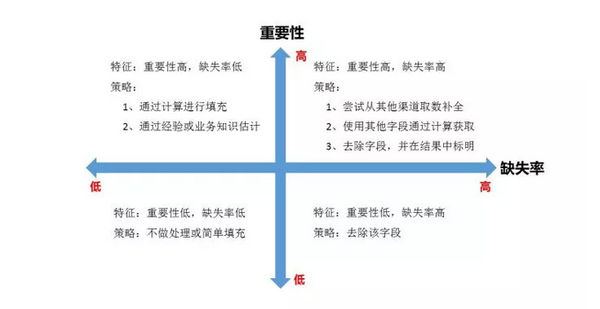
缺失值处理
主要包括少量缺失的情况下,考虑不处理或删除缺失数据或者采用均值、中位数、众数、同类均值填充。 当缺失值对模型影响比较大,存在比较多的不缺失数据的情况下,可以采用模型预测或者插值的方式。当缺失值过多时,可以对缺失值进行编码操作。
删除
均值、中位数、众数、同类均值
建模预测、插值
缺失编码
异常值处理
异常值识别
箱线法
正态分布
异常值检测算法
处理方法
模型预测、插值
删除
分位数截断
模型预测删除
数据转化
文本转数值
图像转数值
标记符号转换
特殊数据转换
特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
我们使用sklearn中的feature_selection库来进行特征选择。
Filter
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用 feature_selection 库的 VarianceThreshold 类来选择特征。
from sklearn.feature_selection import VarianceThreshold
相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用 feature_selection 库的 SelectKBest 类结合相关系数来选择特征。
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr